🏆 123/798 -- 200 points
| Challange | Type | Points | Finished |
|---|---|---|---|
| Fuzzybytes | web | 50 | November 23rd, 6:56:11 PM |
| typstastic | misc | 50 | November 23rd, 5:19:06 AM |
| Rivest–Shamir–Adleman-Germain | crypto | 50 | November 22nd, 9:04:34 PM |
| Welcome | welcome | 50 | November 22nd, 7:02:16 PM |
Learnings#
Embedded PNG files inside PDF stream#
peepdf can help to analyze PDF streams
ImHex is a nice hex editor
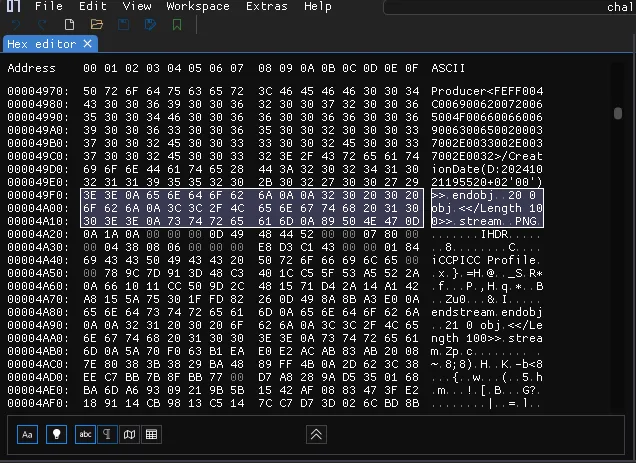
- We can see image data (PNG) is compressed into
xref_streams
Use PyMuPDF library to extract the data
xref_stream()automatically- Locates the stream in the PDF
- Applies the necessary decompression
- Removes any encoding
- Returns the raw binary data
xrefis just a number- It’s the index or ID of each object in the PDF’s cross-reference table
xref // Start of xref table
0 6 // Start at obj 0, contains 6 objects
0000000000 65535 f // Object 0
0000000010 00000 n // Object 1
0000000079 00000 n // Object 2
0000000173 00000 n // Object 3
0000000301 00000 n // Object 4
0000000380 00000 n // Object 5
# In PDF hex dump
stream
789C636400.... # This is compressed data
endstream
# After xref_stream() decoding
89504E470D0A... # Actual PNG data
>>
endobj
20 0 obj // <---- OBJ ID 20
<</Length 100>>
stream
�PNG // <-- PNG starts
- We can then use this script to target the specific stream where the PNG file is via id
20and read the raw data from thexref_stream
import fitz # PyMuPDF
def extract_streams_with_fitz(pdf_path, start_object, output_path):
# Open the PDF
pdf_document = fitz.open(pdf_path)
aggregated_data = b""
# Iterate through all xref objects starting from the specified one
for xref in range(start_object, pdf_document.xref_length()):
try:
# Get the raw stream data
stream_data = pdf_document.xref_stream(xref)
if stream_data:
aggregated_data += stream_data
except Exception as e:
print(f"Failed to process object {xref}: {e}")
continue
with open(output_path, "wb") as f:
f.write(aggregated_data)
print(f"Aggregated PNG data saved to {output_path}")
extract_streams_with_fitz("chall.pdf", 20, "chall.png")